Pears Record Handlers
Contents
Introduction
Document Conventions
What Is a Record Handler?
Record Handlers and Input Record Types
RecordHandler Class Diagram
Record Handler Reference
This document is a reference to the Pears record handlers shipped with SiteSearch 4.2.0. It defines a record handler, explains the relationship between an input record type and a record handler, contains a class diagram for the RecordHandler class package, and lists the required and optional parameters for each record handler.
- <WebZ_root> is the location of your WebZ environment.
In Pears, a record handler is a Java class that:
- converts input records to BER format when you add them to a Pears database
- converts BER records stored in a Pears database to a specified record format and calls internal classes that add the records to an output file
Pears record handlers shipped with SiteSearch 4.2.0 are part of the ORG.oclc.RecordHandler class package. (Except for ORG.oclc.RecordHandler.HandleDB, the record handlers reside in the pears.jar file in <WebZ_root>/classes/lib. HandleDB resides in the <WebZ_root>/classes/lib/SS4_2_0.jar file.)
You can extend these record handlers to work with other input formats or to customize in other ways. If you create custom record handlers, a recommended practice is to put them in your own class package.
Each record handler is associated with an input record type. By convention, record handler class names are Handleinput_record_type, where input_record_type is the record type that the record handle is designed to convert to BER format.
Record Handlers and Input Record Types
inputRecordType Variable in Database Description Configuration File
You specify an input record type with the inputRecordType variable in the [DB] section of the database description configuration file, based on the class name of the associated record handler, like this:
|
Use this format ... |
for record handlers ... |
|
inputRecordType
= SGML
|
in the ORG.oclc.RecordHandler class package. |
| inputRecordType = fully qualified class name | for record handlers you create and add to a custom class package. |
The Pears Bartlett utility looks for a period (.) in the value of the inputRecordType variable. If Bartlett does not find a period in this value, it prepends the string "ORG.oclc.RecordHandler.Handle" to the value and calls the record handler with this name. If Bartlett finds a period, it assumes that the inputRecordType value is a fully qualified class name. In the first example shown above, Bartlett would call ORG.oclc.RecordHandler.HandleSGML. In the second example, Bartlett would call the class indicated.
If you run Bartlett from the command line instead of using SSDOT for Pears, you can also specify the inputRecordType with Bartlett's -c parameter.
| Note: | The inputRecordType value is case-sensitive. If you specified Sgml in the first example above, Bartlett would try to call a nonexistent class, ORG.oclc.RecordHandler.HandleSgml. |
[Handleinput_record_type] in Database Description Configuration File
By convention, the record handler obtains its input parameters from a section in the database description configuration file named [Handleinput_record_type], which matches its class name. If you create your own record handlers, you may wish to establish your own conventions for naming this section.
See Record Handler Reference for the optional and required variables in this section for each record handler.
The following diagram shows the relationships among the RecordHandler classes. Click any of the class names on the diagram to jump to a description of the class and its required and optional parameters.
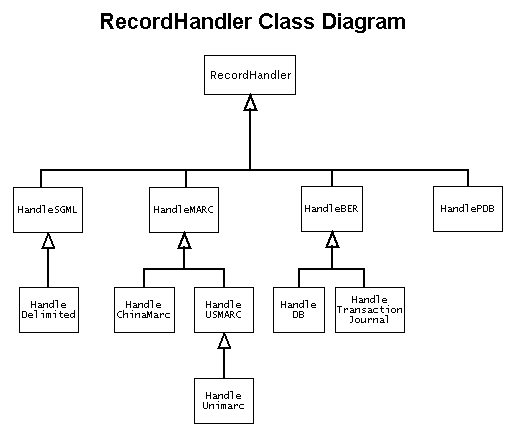
This section contains reference information for these classes in the ORG.oclc.RecordHandler class package:
For each record handler, it describes the variables (its input parameters) that you specify in its section of the database description configuration file. It indicates whether each variable is optional or required, whether it applies to importing and/or exporting records, and whether the variable has a default value. There are also examples of typical sections for several record handlers.
These tables are quick references for creating a record handler section in a database description configuration file. For more technical information about a record handler, see its Javadoc.
RecordHandler is an abstract class that contains a main method for batch data conversion. Other record handler classes extend RecordHandler to enable them to read records from an input data file and convert them to DataDir trees, which eventually become converted to BER records.
The following parameters are available to classes that extend RecordHandler.
|
Parameter |
Description |
||
|
Fully qualified class name of a record filter to use to include or exclude records from the input file from being added to the database. |
||
|
Name of a Java standard ByteToCharConverter. The default is the standard local character set. |
||
|
Name of a Java standard CharToByteConverter. The default is the standard local character set. | ||
|
Name of an OCLC localByteConverter. The only localByteConverter defined is USM94 for USMARC records. The default is the standard local character set. | ||
|
Name of an OCLC localCharConverter. The default is the standard local character set. | ||
|
Tagpath
to a field containing binary data that should not be converted to Unicode. Specify multiple fields with each tagpath on a separate line with a different doNotConvert* variable. |
Running RecordHandler for Test Purposes
You can run RecordHandler from the command line to test a sample of records you want to convert before committing them to a database or to test custom record handler classes that you create. You can run the base RecordHandler class and specify a subordinate class to convert a sample of records to BER format, using these parameters:
This parameter ... specifies the ... RecordHandler class to perform the data conversion. Use the conventions shown for the inputRecordType variable to specify the class name.
-i
name of an input file that contains data records in a specified format.
-o
name of an output file that contains converted records in BER format. -n
number of records to convert.
Example 1 – Convert USMARC records from the file example1.data:
java ORG.oclc.RecordHandler.RecordHandler -cUSMARC -iexample1.data \
-oexample1.ber
Example 2 – Convert the only first 100 USMARC records from the file example1.data:
Java ORG.oclc.RecordHandler.RecordHandler -cUSMARC -iexample1.data \
-oexample1.ber -n100
Example 3 – Convert 1000 records from an existing Newton database to Pears database format:
Java ORG.oclc.RecordHandler.RecordHandler -cDB -inewthedr.db \
-otest.ber -dtestdesc.initestdesc.ini contains only one section, for the character converter:
[HandleDB]
byteConverter = ISO-8859-1
| Note: | In each example, the backslash (\) characters are included only for readability. Do not insert them into the command line. |
| Return to Record Handler List |
| Extends: | RecordHandler |
HandleSGML allows you to import or export SGML or XML records. The records can have a hierarchical structure with multiple levels of tags and/or repeating fields. Each record requires a beginning and ending tag, which you designate in a .tags file. The .tags file maps the fields in the SGML or XML records to the BER tag paths that Bartlett uses to store records in the Pears database.
|
Parameter |
Description |
||||||||
| Parameters inherited from RecordHandler |
See RecordHandler. |
||||||||
|
Full path name of the .tags file that maps the fields in the input file to their BER tag paths in a physical database record. | ||||||||
|
Indicates
that whether to process data in fields that are not listed in the
.tags file. Possible values are:
Setting AllowNewTags=FALSE allows you to use an input file with data in fields that you don't want to add to the database. This affects only the records added to the database and does not modify the input file. |
||||||||
|
Indicates whether to continue to process records from the input file (for importing records) or database (for exporting records) if recoverable error conditions occur. Possible values are:
|
||||||||
|
Indicates whether to combine duplicate non-terminal tags into a single tag when exporting records.
|
||||||||
|
Indicates whether to add a newline character after each closing tag when exporting records. This makes the output more readable by staff members, but may decrease export speed somewhat for a large database. Possible values are:
|
||||||||
|
Indicates whether to add a newline character before and after each record during a record export, using tag designated as the recordTag in the .tags file to determine and start and end of each record. Possible values are:
|
Example
[handlesgml]
tagsFile = <WebZ_root>/dbbuilder/dbs/demosgml/demosgml.tags
newLinesAroundRecord = false
newLinesAfterEveryField = true
ignoreMissingTags = true
| Return to Record Handler List |
| Extends: | HandleSGML |
The HandleDelimited record handler allows you to add data to a Pears database from a delimited text file. Many database and spreadsheet applications allow you to export data to a delimited text file. The default delimiter is a tab, but you can specify another delimiter if necessary, such as a comma.
You can also subsequently export database records imported in delimited text format to an output file in delimited text format.
For importing records, HandleDelimited uses a .tags file to relate fields in the input records to the BER tag paths used to store data from each field in the record. If you do not have a .tags file, HandleDelimited creates a basic .tags file that numbers the fields field001, field002, and so on. The corresponding BER tag paths are assigned sequentially starting at 10.
For exporting records, HandleDelimited requires a Tags file to determine how to create fields in the export file.
|
Variable |
Description |
|||||||
| Parameters inherited from RecordHandler |
See RecordHandler. |
|||||||
|
Parameters inherited from HandleSGML |
See HandleSGML. |
|||||||
|
Indicates whether to trim leading white space from fields in input records when importing records. Possible values are:
Removing the white space may result in records that are easier to format for display. However, if you subsequently export these records, they no longer contain the white space contained in the original records. |
|||||||
|
Indicates that the data contains a backslash to delimit fields that themselves contain the delimiter used to separate fields in the data file (such as \John Doe, Jane Doe\, in a comma-delimited file.
|
|||||||
|
Indicates that the data contains double quotes (") to delimit fields that themselves contain the delimiter used to separate fields in the data file (such as "John Doe, Jane Doe", in a comma-delimited file.
|
|||||||
|
Character(s) used to separate fields within a record in the input file (import) or output file (export). The default value is a tab (\t). | |||||||
|
Character(s) used to separate repeating data elements in a single field within a record in the input file (import) or output file (export). The default value is a semicolon (;). | |||||||
|
Indicates whether the first record in the input file contains field labels for the data records in the rest of the file.
|
|||||||
|
Indicates whether to add only a newline character at the end each record when exporting records to a file. Possible values are:
|
|||||||
|
Indicates whether to collapse a record's tree structure by combining fields in a record with common tag paths (such as a repeating field) and records with a common base tag (such as 102/1001/1001 and 102/1002/1001) into a single field. Possible values are:
Collapsing the tree occurs only in the records contained in the export output file. It has no effect on the data stored in the database. |
Example
[HandleDelimited]
tagsFile = <WebZ_root>/dbbuilder/dbs/demodelimited/demodelimited.tags
delimiters =\t
repeatDelimiter = ;
FirstRecordHasTags=true
EscapeWithQuotes = true
terminateRecordWithNewLineOnly = false
| Return to Record Handler List |
HandleMARC, HandleChinaMarc, HandleUSMARC, HandleUnimarc
| Extends: | See the class diagram for inheritance among these classes. |
These classes allow you to import and export records in standard MARC, ChinaMarc, US MARC, and Unimarc, respectively. Each class has the same input parameters, as shown below.
|
Parameter |
Description |
|||||||
| Parameters inherited from RecordHandler |
See RecordHandler. |
|||||||
|
Indicates whether to continue to process records from the input file (for importing records) or database (for exporting records) if recoverable error conditions occur. For MARC records, errors occur primarily when converting diacritics to Unicode characters. Possible values are:
|
|||||||
|
Specifies characters, that if found in the Record Status field in the MARC Leader, mean that the record should be deleted. The default is to ignore the Record Status field. |
| Return to Record Handler List |
| Extends: | RecordHandler |
HandleBER adds BER records to a Pears database.
|
Parameter |
Description |
| Parameters inherited from RecordHandler. |
See RecordHandler. |
| Return to Record Handler List |
| Extends: | HandleBER |
The HandleDB record handler converts records from a Newton database (.db) to the format required by a Pears database (.pdb) by reading records from the Newton HEDR database file (dbnamehedr.db). HandleDB expects to find the Newton HDIR file in the same directory as the HEDR file and to have the same dbname characters in its name (that is, dbnamehdir.db).
|
Parameter |
Description |
|
Parameters inherited from RecordHandler. |
See RecordHandler. |
| Return to Record Handler List |
| Extends: | HandleBER |
HandleTransactionJournal adds transactions stored in a Pears journal file to a Pears database. You can use this record handler for database recovery, when you restore a database backup and then add transactions from one or more journal files to bring the database back up to date.
|
Parameter |
Description |
| Parameters inherited from RecordHandler |
See RecordHandler. |
| Return to Record Handler List |
| Extends: | RecordHandler |
HandlePDB extracts records from an existing Pears database. SSDOT for Pears uses HandlePDB during database reorganization. You can also use it to extract records from a Pears database and store them in an external file in BER format.
|
Parameter |
Description |
|
Parameters inherited from RecordHandler |
See RecordHandler. |
| Return to Record Handler List |
See Also
Pears
Database Description Configuration File
Creating a New Pears Database
Pears System Overview